

Navigating the high-speed highway of Large Language Models (LLMs) inference is akin to threading a needle while riding a rollercoaster. However, their need for computational snacks grows exponentially as they bulk up in size and smarts. This creates a conundrum that's both fascinating and a headache.
Imagine trying to have a lightning-fast chat with a wise old sage who, despite his vast knowledge, takes his sweet time to ponder each answer. That's our modern-day digital dilemma. To keep the conversation flowing smoothly, without those awkward silences, engineers play the role of tech wizards. They pull tricks out of their hats, like quantization, pruning, and crafting sleek serving architectures, striving to make these digital sages not just wiser but quicker on their feet.
Yet, every magic trick comes with its own cost—a dip in the model's performance or the sheer energy and resources needed to keep the show going. This balancing act between speed and smarts, efficiency and effectiveness, highlights a thrilling challenge in the AI world.
What actually is TTFT
When discussing the performance of Large Language Models (LLMs) like GPT-3, GPT-4, or other similar models, two critical metrics often come into play: inference speed and Time To First Token (TTFT). These metrics are pivotal for understanding how efficiently these models can generate responses and how they impact the user experience in real-time applications.
Inference Speed
Inference speed refers to how quickly a model can process input and produce a response after receiving a query. This metric is crucial for real-time applications, such as chatbots, virtual assistants, and interactive tools, where responsiveness is key to maintaining engagement and providing value to the user. The inference speed of an LLM is influenced by several factors:
- Model Size: Larger models, with more parameters, generally take longer to process inputs due to the increased computational complexity. However, they often provide more accurate and contextually rich responses.
- Hardware: The speed of inference is significantly affected by the hardware used for model deployment. High-performance GPUs, TPUs, or specialized hardware accelerators can greatly reduce inference times.
- Optimization Techniques: Techniques such as quantization, pruning, and knowledge distillation can reduce model size and complexity, improving inference speed without substantially sacrificing performance quality.
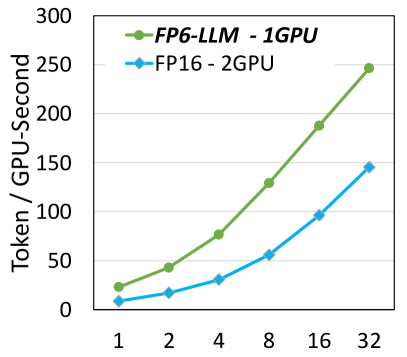
Time To First Token (TTFT)
Time To First Token (TTFT) is a specific metric within the broader category of inference speed, focusing on the time it takes for the model to produce the first token of its response. This metric is particularly relevant in conversational AI, where the perception of speed and responsiveness is critical to user satisfaction. TTFT is influenced by:
- Initial Processing Time: Before generating a response, the model must process the input, understand the context, and initiate the response generation process. This initial step contributes to the TTFT.
- Model Architecture: Some models are designed to optimize for quicker initial responses. For example, models that can generate tokens in parallel or have been optimized for faster initial inference can achieve lower TTFT.
- Caching and Predictive Loading: Techniques like caching common responses or pre-loading parts of the model based on anticipated inputs can also reduce TTFT, making the interaction feel more immediate to the user.
The OpenLLM Leaderboard Shortfall
The Open LLM Leaderboard is a pivotal resource for benchmarking and comparing the capabilities of large language models (LLMs) and chatbots across various dimensions. By leveraging the EleutherAI Language Model Evaluation Harness, it offers a comprehensive evaluation across a spectrum of benchmarks, including science questions, commonsense inference, multitask accuracy, and truthfulness in generating answers. These benchmarks are meticulously designed to test models' reasoning, general knowledge, and adaptability in both 0-shot and few-shot settings, providing a well-rounded view of their capabilities.
However, despite the depth and breadth of metrics available, one critical piece of information notably absent from the leaderboard is the "time to first token" metric (TTFT). This metric measures the speed at which a model begins generating a response after receiving a prompt, serving as a key indicator of its efficiency and responsiveness in real-world applications. The lack of this data leaves a gap in understanding the practical usability of these models, especially in time-sensitive environments where rapid response times are crucial. Including TTFT information would not only offer a more holistic view of a model's performance but also help stakeholders gauge its suitability for applications requiring quick interactions, such as conversational AI, real-time decision-making systems, and interactive educational tools. Without it, the leaderboard, while rich in evaluating cognitive and linguistic capabilities, misses a vital aspect of performance that impacts user experience and operational efficiency.
So how is this different from throughput?
In the realm of system performance evaluation, two key metrics often come into play: Throughput and TTFT (Time to First Transaction). While both metrics gauge the efficiency and responsiveness of a system, they address different aspects of its performance. Let's delve into each of these metrics to understand their significance and how they differ.
Throughput: Measuring Efficiency
Throughput is a fundamental metric used to assess the rate at which a system or process can handle tasks, process data, or complete transactions within a given timeframe. It essentially quantifies the system's capacity to process work efficiently. Throughput is typically expressed as the number of transactions, operations, or data units processed per unit of time, such as transactions per second (TPS) or operations per minute (OPM).
For instance, in a manufacturing environment, throughput might represent the number of units produced per hour, while in a computer network, it could denote the data packets transmitted per second. In essence, higher throughput indicates better efficiency and capacity utilization of the system.
TTFT (Time to First Transaction): Assessing Responsiveness
TTFT, on the other hand, zooms in on the initial responsiveness of a system from the moment it is activated until it can handle the first transaction. It measures the time elapsed between the initiation of the system or process and the completion of the first transaction. TTFT is particularly crucial in scenarios where quick response times are paramount, such as real-time systems or interactive applications where users expect near-instantaneous feedback.
Consider an e-commerce platform where users expect rapid response times upon clicking on a product link. The TTFT metric would gauge how quickly the system processes the user's request and displays the relevant product page. Minimizing TTFT ensures a smoother user experience and enhances customer satisfaction.
Key Differences and Importance
While both throughput and TTFT are essential metrics for evaluating system performance, they serve distinct purposes:
- Throughput focuses on the overall efficiency and capacity of a system over time, reflecting its ability to handle a continuous stream of work or transactions.
- TTFT hones in on the initial responsiveness or latency of the system, providing insights into its ability to promptly handle the first transaction after activation.
Understanding the differences between these metrics is crucial for effectively assessing and optimizing system performance. While high throughput signifies robust capacity and efficiency, minimizing TTFT enhances the system's responsiveness and user experience.
In conclusion, both throughput and TTFT play pivotal roles in evaluating and optimizing the performance of systems across various domains. By leveraging these metrics effectively, organizations can enhance the efficiency, responsiveness, and overall effectiveness of their systems and processes
Difference in Speed with LLM type
Latency, especially in the context of Large Language Models (LLMs), plays a crucial role in determining their practical utility, especially in real-time applications where responsiveness is paramount. When comparing encoder-only, decoder-only, and encoder-decoder LLMs, their respective architectures and computational requirements significantly impact latency.
- Encoder-only LLMs:
- Architecture: Encoder-only LLMs, such as BERT (Bidirectional Encoder Representations from Transformers), focus solely on encoding input sequences. They generate contextualized representations of input tokens but do not perform generation tasks directly.
- Latency Characteristics: Encoder-only LLMs typically have lower latency compared to decoder-only and encoder-decoder LLMs. Since they do not involve the generation process, the latency primarily depends on the encoding phase, which tends to be faster.
- Decoder-only LLMs:
- Architecture: Decoder-only LLMs, exemplified by GPT (Generative Pre-trained Transformer) models, are designed specifically for generation tasks. They generate sequences token by token based on context and learned representations.
- Latency Characteristics: Decoder-only LLMs generally exhibit higher latency compared to encoder-only LLMs. This is because they involve not only encoding but also decoding and generating tokens sequentially, which can be computationally intensive and time-consuming, especially for longer sequences.
- Encoder-decoder LLMs:
- Architecture: Encoder-decoder LLMs, like BART (Bidirectional and Auto-Regressive Transformers), combine both encoding and decoding components. They are well-suited for tasks requiring both understanding and generation, such as machine translation and text summarization.
- Latency Characteristics: The latency of encoder-decoder LLMs lies between that of encoder-only and decoder-only models. While they inherit the encoding efficiency of encoder-only models, the additional decoding and generation steps contribute to increased latency compared to pure encoders.
.png)
Filters taken into consideration & Code
For our experiment, we have decided to solely focus on chat models that have not been fine-tuned for a specific task. This decision has been made to preserve the practical integrity of our experiment. By choosing such models, we ensure our experiment's results have broader applicability and are not skewed towards a particular domain. This approach aligns with our desire for our applications to be domain-agnostic, allowing them to be versatile and adaptable across a wide range of scenarios.
Here’s the models we are testing out.

- yleo/EmertonMonarch-7B: A 7-billion-parameter model requiring 15 gigabytes of disk space and completing the task in a swift 1.21 units of time.
- touqir/Cyrax-7B: Another 7-billion-parameter model, mirroring its counterpart in size and performance with 15 gigabytes of disk space and a time of 1.22 units.
- vicgalle/ConfigurableBeagle-11B: This 11-billion-parameter model demanded 22 gigabytes of disk space and clocked in at 2.34 units of time.
- yunconglong/Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B: A dual 7-billion-parameter model, slightly larger in disk space at 24.85 gigabytes and completing the task in 2.68 units of time.
- zhengf/MixTAO-7Bx2-MoE-Instruct-v7.0: Yet another dual 7-billion-parameter model, occupying 26 gigabytes of disk space and taking 2.7 units of time.
- vicgalle/CarbonBeagle-11B-truthy: Similar in size to its predecessor, this 11-billion-parameter model required 22 gigabytes of disk space but took a bit longer at 3.52 units of time.
- dddsaty/FusionNet_7Bx2_MoE_Ko_DPO_Adapter_Attach: Another dual 7-billion-parameter model, sharing similar disk space requirements with its counterparts but taking 3.58 units of time.
- moreh/MoMo-72B-lora-1_8_7-palm: A colossal 72-billion-parameter model, demanding a whopping 304 gigabytes of disk space and completing the task in 4.21 units of time.
- moreh/MoMo-72B-lora-1_8_6-palm: Similar in size and performance to its sibling, occupying the same disk space and completing the task in 4.22 units of time.
- moreh/MoMo-72B-lora-1_8_4-palm: Completing the trio of mammoth models, this variant shared identical specifications with its counterparts.
The code we've developed for our experiment is provided here. At its core, the function of this code is to generate a single token and measure the time taken to accomplish this. This process is instrumental in our study, as it allows us to evaluate the efficiency of the algorithm we're using.
To execute this code, you'll need to have the transformers library installed on your system. If you do not already have this library, it can be easily installed.
! pip3 install transformers accelerate bitsandbytes
- Importing Libraries and GPU usage
Let's import the necessary libraries and make sure we are efficiently using our GPU for faster computation.
- Load the tokenizer and model
8-bit quantization compresses model weights and activations into a limited range of values, optimizing memory usage and inference speed, akin to simplifying complex neural networks into more manageable forms without compromising performance. we are also setting up float16 for computations to further optimize memory usage.
- Pipeline Generation and CPU fallback
This pipeline creates a text generator using the specified model and tokenizer, leveraging GPU if available, or falling back to CPU for computation, facilitating efficient text generation across hardware configurations.
- Truncation and calculation of TTFT (Time to First Token)
This code snippet generates text using a pre-trained model, measuring the time taken to generate the first token. It employs settings like truncation, sampling, and maximum length to control the generation process, handling exceptions gracefully.
Testbench and Setup
So at first and at the time of this article’s inception, I went: Surely I can run these models on a free-tier google colab right? WRONG. The setup we are using to test these models are as follows:
Hardware Specifications:
- GPU: NVIDIA A100 with 80 GB VRAM
- CPU: 24 vCPUs (Virtual Central Processing Units)
- RAM: 117 GB
- Storage: 250 GB
Results
- yleo/EmertonMonarch-7B: A 7-billion-parameter model requiring 15 gigabytes of disk space and completing the task in a swift 1.21 units of time.
- touqir/Cyrax-7B: Another 7-billion-parameter model, mirroring its counterpart in size and performance with 15 gigabytes of disk space and a time of 1.22 units.
- vicgalle/ConfigurableBeagle-11B: This 11-billion-parameter model demanded 22 gigabytes of disk space and clocked in at 2.34 units of time.
- yunconglong/Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B: A dual 7-billion-parameter model, slightly larger in disk space at 24.85 gigabytes and completing the task in 2.68 units of time.
- zhengf/MixTAO-7Bx2-MoE-Instruct-v7.0: Yet another dual 7-billion-parameter model, occupying 26 gigabytes of disk space and taking 2.7 units of time.
- vicgalle/CarbonBeagle-11B-truthy: Similar in size to its predecessor, this 11-billion-parameter model required 22 gigabytes of disk space but took a bit longer at 3.52 units of time.
- dddsaty/FusionNet_7Bx2_MoE_Ko_DPO_Adapter_Attach: Another dual 7-billion-parameter model, sharing similar disk space requirements with its counterparts but taking 3.58 units of time.
- moreh/MoMo-72B-lora-1_8_7-palm: A colossal 72-billion-parameter model, demanding a whopping 304 gigabytes of disk space and completing the task in 4.21 units of time.
- moreh/MoMo-72B-lora-1_8_6-palm: Similar in size and performance to its sibling, occupying the same disk space and completing the task in 4.22 units of time.
- moreh/MoMo-72B-lora-1_8_4-palm: Completing the trio of mammoth models, this variant shared identical specifications with its counterparts.

Key Findings
Our benchmarking test yielded several noteworthy findings:
- Efficiency vs. Scale: While larger models tend to offer superior performance, they often come at the cost of increased disk space and computational time. Strike the right balance based on your specific requirements.
- Dual-Model Architectures: Models employing dual architectures showcased competitive performance metrics, leveraging the combined power of multiple models.
- Resource Requirements: As expected, the resource requirements—both in terms of disk space and time—scaled linearly with model size, underscoring the importance of efficient resource management.
.png)
Conclusion
Our benchmarking test offers a snapshot of the cutting-edge, providing valuable insights into the performance and resource demands of large language models. To shed light on the current state of the art, we conducted a comprehensive benchmarking test on some of the most formidable contenders in the field.
Need help choosing the best LLM?
At Ionio, we specialize in delivering top-notch LLM services tailored to your specific needs. Whether you're looking to harness the power of existing models or develop custom solutions, our team of experts is here to guide you every step of the way. Ready to unlock the full potential of NLP for your organization? Get in touch with us today to embark on your journey towards transformative language solutions.
.png)