ControlNet emerges as a groundbreaking enhancement to the realm of text-to-image diffusion models, addressing the crucial need for precise spatial control in image generation. Traditional models, despite their proficiency in crafting visuals from text, often stumble when it comes to manipulating complex spatial details like layouts, poses, and textures. ControlNet innovatively bridges this gap by locking the original model parameters and introducing a trainable layer equipped with "zero convolutions." These unique layers, which start from zero and adapt over time, ensure a finetuning process devoid of harmful noise, maintaining the integrity of the pretrained models. Compatible with Stable Diffusion, ControlNet adeptly manages various conditions—edges, depth, segmentation, human pose—enhancing the model's flexibility. Through rigorous testing, ControlNet has proven its versatility, signaling a new era of controlled and creative image generation, and setting the stage for unprecedented visual creativity.
Understanding ControlNet
The Genesis of ControlNet
The journey of ControlNet began with an exploration into the limitations faced by users of Stable Diffusion models. These powerful models have democratized access to high-quality image generation, enabling anyone with a prompt to create stunning visuals. However, the nuanced control over the spatial arrangement, precise object shapes, and specific compositional elements remained elusive. Digital artists found themselves iterating countless times to achieve visuals that matched their internal vision, often compromising on their creative intent in the process.
Recognizing this challenge, the creators of ControlNet sought to enhance the Stable Diffusion framework by incorporating mechanisms for spatial conditioning. This endeavor is detailed in the research paper "Adding Conditional Control to Text-to-Image Diffusion Models" by Lvmin Zhang, Anyi Rao, and Maneesh Agrawala of Stanford University, available at arXiv:2302.05543. Their work led to the development of a novel architecture capable of integrating additional image-based inputs, such as sketches, depth maps, or segmentation maps, alongside text prompts. This integration enables the model to adhere closely to the artist's intended composition, shape, and layout, offering a direct pathway from imagination to digital canvas. Through the innovations presented by Zhang, Rao, and Agrawala, ControlNet emerges as a transformative tool in the landscape of AI-driven creativity, bridging the gap between the artist's vision and the capabilities of generative models.
ControlNet architecture in depth
The architecture of ControlNet is built on two foundational pillars: the preservation of the pre-trained diffusion model's strengths and the introduction of spatial conditioning controls through a novel use of zero-initialized convolutional layers, termed "zero convolutions."
Preservation of Pre-trained Model
ControlNet treats the original diffusion model as a sacred backbone, locking its parameters to preserve the quality and knowledge encapsulated within. This approach ensures that the deep, nuanced understanding of visual content, learned from vast datasets, remains intact and effective.
Spatial Conditioning with “Zero Convolutions”
.png)
The true innovation of ControlNet lies in its spatial conditioning mechanism. By introducing zero convolutions, ControlNet adds a layer of control that starts from a point of non-influence—essentially a blank slate. These convolutional layers are unique because they begin with weights and biases set to zero, meaning they have no initial effect on the image generation process. However, during training, these layers learn to modulate the influence of spatial conditions (e.g., sketches, poses, depth maps) on the generation process. This learning is gradual and controlled, preventing any abrupt disruptions to the model's pre-learned knowledge base.
The architecture facilitates a delicate balance, allowing the original model to continue operating as designed while simultaneously learning to incorporate new, spatially-relevant information. The result is a model that not only understands the textual prompt but also respects the spatial cues provided by the user, enabling a much richer, more controlled generative process.
How Does ControlNet Do Its Magic?
Imagine Stable Diffusion as a vast library of images and styles it has learned from millions of pictures. ControlNet taps into this library but does so in a way that's akin to having two versions of the book: one that's kept pristine (the "locked copy") and another that's a working copy where notes can be made (the "trainable copy").
The locked copy is like the wisdom of ages—it doesn't change. It ensures that the rich knowledge gained from training on vast datasets remains intact. The trainable copy, on the other hand, is where ControlNet learns to apply your specific instructions, be they text or images like sketches or photos.
Connecting these two versions is a unique bridge called "zero convolution." Think of it as a bridge made of invisible ink that slowly reveals itself. Initially, it doesn't influence the crossing traffic (the process of generating your image), but as it learns from your specific tasks, it starts to guide the traffic in ways that align with your instructions. This setup ensures that the vast knowledge base is not disturbed while still adapting to new, specific tasks.
The Training Journey
Training ControlNet is like teaching it to understand and follow your specific creative wishes. It looks at lots of examples, learning how to interpret various conditions from both text prompts and input images. Because of the ingenious setup with zero convolutions, this training is efficient—it doesn't start from scratch but builds on the massive knowledge base of the locked copy, fine-tuning the model to your needs without forgetting what it has already learned.
Key Settings in Simple Terms
When you're using ControlNet, you'll come across a few settings that help fine-tune how it follows your directions:
- Input Controls: Here, you can upload an image, draw directly, or even snap a photo to use as a guide. This guide helps ControlNet understand the visual part of your creative intent.
.png)
- Model Selection: This lets you choose how much of ControlNet's power you want to harness, with options tailored for different system capabilities.
.png)
- Control Weight and Steps: These settings are about balancing the influence of your visual guide against the textual prompt. You can adjust how strongly ControlNet should "listen" to the visual guide from the beginning, middle, and end of the image creation process.
.png)
- Control Mode: This determines how much priority your visual instructions have over the text prompt throughout the creative process.
.png)
- Resize Mode: Since the guide image and the final image might have different sizes, this setting helps decide how the guide should be adapted to fit the creative canvas.
.png)
Merging ControlNet with Stable Diffusion
Think of Stable Diffusion as an expert painter who can create a wide array of images based on textual descriptions. Now, enter ControlNet, a new set of skills for our painter, enabling them to understand and incorporate visual cues like sketches or photos into their artwork.
The integration begins with ControlNet making a "trainable copy" of Stable Diffusion’s neural network. This copy is where ControlNet learns to apply visual instructions without disturbing the original model. It’s akin to an apprentice painter learning from a master without changing the master's original techniques.
At the same time, the "locked copy" of Stable Diffusion ensures that the foundational knowledge, gained from training on millions of images, remains untouched. This way, ControlNet benefits from the best of both worlds: the depth and breadth of Stable Diffusion’s capabilities and the nuanced understanding of visual conditions brought by ControlNet.
.png)
Conditional Controls and Control Vectors
Now, onto the heart of ControlNet's customization prowess: conditional controls and control vectors. These are essentially the channels through which you communicate your visual instructions to the AI.
- Conditional Controls: Imagine you're directing a movie and have the power to decide not just the storyline but also the precise appearance of every scene, the lighting, the mood, and the characters' poses. Conditional controls in ControlNet give you similar directorial power over the image generation process. Whether you want to maintain the pose from a reference image, stick to a specific layout, or ensure that the generated image has certain textural characteristics, these controls are your tools.
- Control Vectors: These are the technical backbone that enables the application of conditional controls. When you provide a sketch, a photo, or any visual input, ControlNet translates these into a language (vector) that the AI understands. This translation process involves creating a detailed map (control vector) of the input image's features, such as edges, depth, or segmentation. ControlNet then guides the image generation process using this map, ensuring that the final image aligns with your visual inputs as closely as possible.
The foundational concept of ControlNet revolves around the integration of additional, task-specific conditions into the processing of a neural network, particularly a large, pretrained model like Stable Diffusion. This is achieved through a strategic modification and training process that allows for the incorporation of external conditioning vectors without disrupting the pretrained model's integrity.
.png)
Mathematical Formulation
- Neural Block Transformation:
Consider a neural block F(⋅;Θ) that transforms an input feature map x into another feature map y:
y=F(x;Θ)
Here, x and y are 2D feature maps with dimensions h×w×c, where ℎ, w, and c represent the height, width, and number of channels, respectively. Θ represents the parameters (weights and biases) of the neural block.
- Introducing of ControlNet:
ControlNet introduces a "trainable copy" with parameters Θc and a "locked copy" that preserves the original parameters Θ. The innovative aspect of ControlNet lies in its use of zero-initialized convolution layers, denoted as Z(⋅;⋅), to blend these copies based on an external conditioning vector c.
The trainable copy processes the input feature map x and the conditioning vector c, while the original neural block remains untouched. The output of the ControlNet-enhanced block, yc, is computed as follows:
yc=F(x;Θ)+Z(F(x+Z(c;Θz1);Θc);Θz2)
In this equation:
Z(c;Θz1) and Z(⋅;Θz2) represent the zero-initialized convolution layers with their respective parameters. Initially, these layers have no effect (Z(c;Θz1)=0) since their weights and biases are set to zero.
F(x;Θ) is the output from the original, locked neural block.
F(x+Z(c;Θz1);Θc) is the output from the trainable copy, which processes both the input feature map and the conditioned feature map adjusted by Z(c;Θz1).
- Advantages of Zero Convolution Layers:
The zero convolution layers ensure that the training process begins without introducing harmful noise into the deep features of the model. This strategic approach allows for the gradual and controlled adaptation of the model to incorporate the external conditioning vectors, thus maintaining the integrity of the pretrained model's knowledge while enabling customization based on the conditioning vector c.
- Training and Optimization:
The training objective for integrating ControlNet into a diffusion model involves minimizing the difference between the predicted noise ϵ and the actual noise added to the image at each diffusion step. Given a set of conditions including time step t, text prompts ct, and a task-specific condition cf, the loss function can be represented as:
L=Ez0,t,ct,cf,ϵ∼N(0,1)[∥ϵ−ϵθ(zt,t,ct,cf)∥22]
This optimization process ensures that ControlNet learns to apply the conditional controls effectively, adapting the image generation process according to both textual and visual cues provided by the user.
During inference, ControlNet allows for detailed customization of the image generation process, leveraging the learned conditional controls to produce images that align closely with both the textual descriptions and the provided conditional vectors (e.g., sketches, depth maps). This mathematical framework underpins the ability of ControlNet to serve as a robust and flexible tool for enhancing the capabilities of large-scale image generation models, offering unprecedented control and customization options to the users.
Achieving Detailed Customization
The beauty of ControlNet lies in its ability to achieve detailed customization through a delicate balancing act. It adjusts the influence of your visual guides (through control weights and steps) against the text prompt, allowing for precise tuning of the final output. You get to decide which aspects of your visual guide are most important and should be emphasized in the generated image.
For instance, if you're using a sketch of a landscape as your guide but want the AI to fill in specific details like sunset colors or autumn leaves, you can adjust the control weights to prioritize the landscape's outline while letting the AI creatively fill in the details as per the text prompt.
In essence, ControlNet transforms image generation by making the AI more attuned to visual inputs, leading to outputs that are not just inspired by your text prompts but are also shaped by your visual imagination. This integration of visual and textual inputs, powered by ControlNet, opens up new horizons for personalized and detailed image creation, making it an invaluable tool for artists, designers, and anyone looking to bring their vivid imaginations to life.
Types of ControlNet Models
.png)
Scribble Model
The Scribble model is engineered to interpret loosely defined input shapes and color indications provided by users' scribbles. At a technical level, this model employs a convolutional neural network (CNN) architecture that is fine-tuned to recognize and extrapolate the spatial and color information from simple, user-generated scribbles. The model translates these inputs into high-resolution, detailed images by mapping the scribble patterns to learned representations of real-world textures and objects.
.png)
Mechanism:
- Input Processing: Scribbles are processed through a series of convolutional layers that extract feature maps at various levels of abstraction.
- Feature Mapping: The extracted features are then matched with learned representations within the model, allowing for the interpretation of scribbles as indicative of certain textures, shapes, or color schemes.
- Image Generation: Using a generative adversarial network (GAN) framework, the model synthesizes detailed images that align with the abstract input while ensuring photorealism and coherence in the generated output.
Depth Model
The Depth model specializes in interpreting grayscale images representing depth information, where lighter areas correspond to closer objects and darker areas to objects further away. This model leverages depth cues to render images with realistic spatial relationships and perspectives.
.png)
Mechanism:
- Depth Cue Interpretation: Utilizes a CNN to interpret depth information from the input map, distinguishing between foreground and background elements based on grayscale intensity.
- 3D Spatial Modeling: Through a series of depth-wise convolutional layers, the model constructs a 3D spatial understanding of the scene, enabling it to accurately model how objects interact within a space.
- Photorealistic Rendering: Integrates depth-based spatial understanding with texture and color information learned from the dataset to generate images that not only respect the input depth cues but also exhibit realistic lighting and shadow effects.
OpenPose Model
The OpenPose model is designed to generate images based on human pose estimations. It interprets skeletal data, identifying key points in the human body and generating images of humans in specified poses.
.png)
Mechanism:
- Pose Estimation Processing: This model processes input skeletal data using a CNN, identifying key points and pose structures.
- Pose-to-Image Synthesis: Utilizing a conditional GAN (cGAN), the model synthesizes human figures in the desired poses, ensuring anatomical accuracy and realistic posture representation.
- Detail and Texture Application: The model then applies textures, clothing, and environmental details to the synthesized figures, referencing learned representations from a comprehensive dataset of human images.
Segmentation Map Model
This model interprets color-coded segmentation maps, where different colors represent distinct objects, materials, or elements within a scene. It is adept at generating complex scenes with accurately placed and rendered components.
.png)
Mechanism:
- Segmentation Interpretation: A CNN processes the segmentation map, identifying each color-coded region and its corresponding object or material category.
- Scene Composition: Based on the interpreted segmentation, the model constructs a coherent scene layout, placing each identified element in its designated location within the image frame.
- Element Rendering: Leveraging a cGAN framework, the model renders each element in the scene with appropriate textures, colors, and lighting, guided by the conditional controls provided by the segmentation map.
Canny Edge Model
Inspired by the Canny edge detection algorithm, this model interprets edge maps as the skeletal framework for image generation. It focuses on generating images that respect the outlined shapes and structures presented in the edge map.
.png)
Mechanism:
- Edge Detection Processing: Processes the edge map through a CNN, identifying edges and outlines as primary structures for the subsequent image generation.
- Structural Interpretation: The model interprets these edges as boundaries of objects, textures, or elements within the scene, using learned patterns from training data.
- Image Synthesis: Employing a GAN, the model fills in the outlined structures with realistic textures, colors, and details, effectively transforming the edge map into a detailed, coherent image.
Understanding T2I-Adapters and ControlNets: A Deep Dive
T2I-Adapters: The Agile Artists
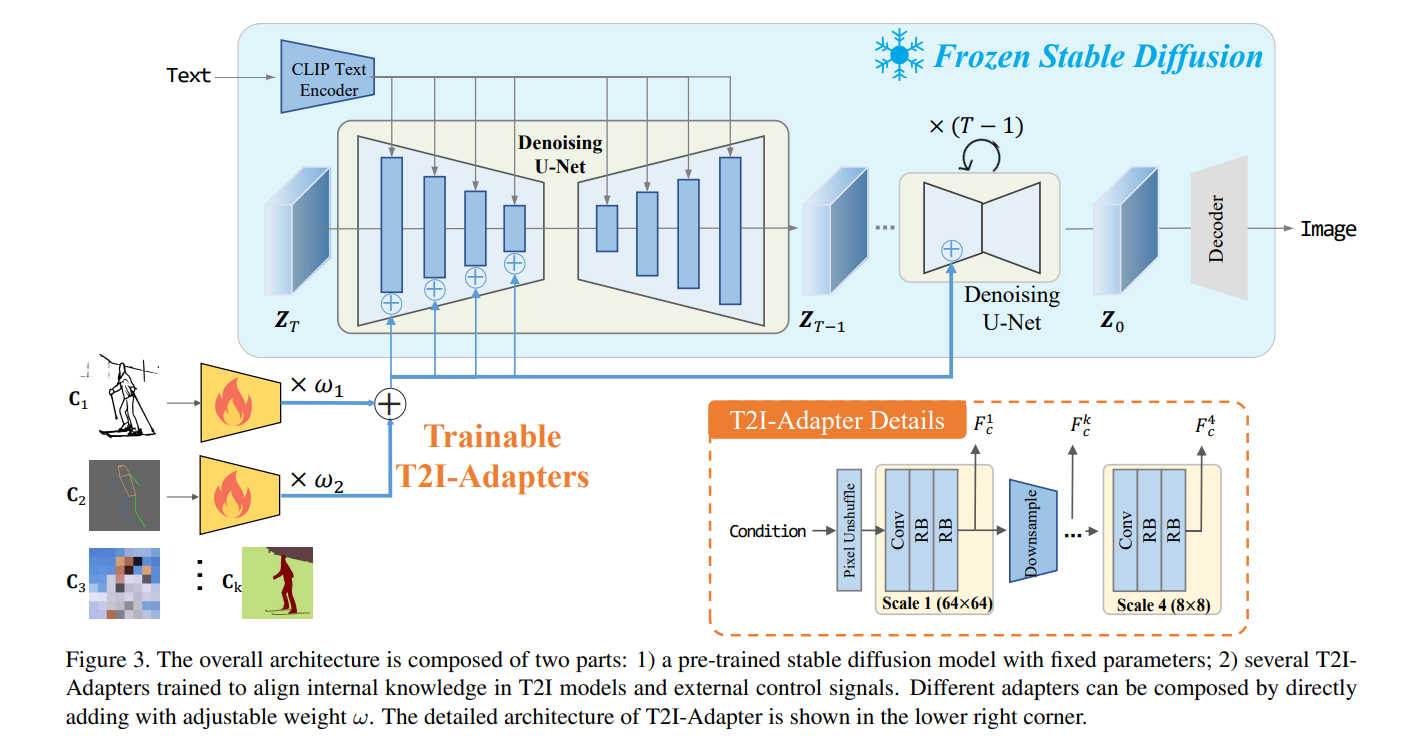
Imagine you're working with a seasoned painter who's great at adding layers to a masterpiece to bring out the best in light, shadows, and details, all based on your suggestions. That's akin to what T2I-Adapters do in the digital realm. They're nimble and adept at tweaking existing neural network models to respond to new textual prompts more effectively.
- Technical Edge: T2I-Adapters act like plugins or enhancements to your existing neural network, enabling it to understand and act on textual descriptions with more nuance and precision. They do this without the need for a major overhaul, making them a go-to choice for projects where time and computational resources are of the essence.
- When to Use: T2I-Adapters shine when you want to subtly alter the output of your image generation model based on text – think adjusting the mood of a landscape or the attire of a character in a scene. They're perfect for tasks that require a gentle nudge rather than a complete directional change.
Why Pick T2I-Adapters for Certain Tasks?
.png)
While both tools offer incredible capabilities, there are times when the agility and precision of T2I-Adapters make them the artist of choice:
- Quick Changes: If you're looking to quickly iterate on styles, themes, or minor details based on textual prompts, T2I-Adapters allow for fast, efficient adjustments. They're like being able to whisper changes into the ear of an artist who can instantly bring them to life.
- Resource Conservation: In the digital studio of neural networks, computational resources are akin to paint and canvas – you want to use them wisely. T2I-Adapters require less computational "material" to achieve significant alterations, making them cost-effective for projects where resources are limited.
- Subtle Refinements: Sometimes, all a masterpiece needs is a slight retouching to capture the perfect mood or detail. T2I-Adapters excel at making these fine adjustments, ensuring that the output aligns precisely with the textual narrative, enhancing the image's overall impact and coherence.
In essence, choosing between T2I-Adapters and ControlNets depends on the scope and nature of your project. If you're after agility, subtlety, and resource efficiency, T2I-Adapters offer a streamlined pathway to enriching your neural network's response to text. Meanwhile, for those ventures where depth, detail, and the integration of complex visual inputs are key, ControlNets stand ready to sculpt your ideas into stunning digital realities.
Discover Creativity Unleashed with Ionio
Ionio brings the future of digital creativity to your fingertips, blending the pioneering ControlNet with our Generative AI suite. Designed for artists, developers, and innovators, our platform transforms your creative process, marrying AI's power with user-centric design.
Ready to redefine digital creation? Connect with us today and unlock a world of endless possibilities, where I, with our founder Rohan Sawant, will discuss how our blend of ControlNet and Stable Diffusion can elevate your projects beyond imagination.
Start your creative revolution with Ionio.ai now.