Introduction
Model merging combines multiple pre-trained large language models into one powerful model that takes advantage of their collective strengths. This guide explores different merging techniques like Model Soups, SLERP, Task Arithmetic, TIES, and Mixture of Experts using the open-source MergeKit library. It provides a hands-on implementation to merge models and improve their performance and efficiency.
⭐ You can refer to the enclosed code here
What is Model Merging?
Daily, we're seeing more and more Large Language Models (LLMs) being developed and used. As these models get bigger, they also become more expensive to train. A well-known and effective LLM is GPT-3, which can range from 125 million to 175 billion parameters in size. Using 1,024x A100 GPUs it took OpenAI 34 days and cost $4.6M in compute alone to train the LLM model.
Normally, to improve the accuracy of any model we,
1. Fine-tune the model on a larger and diverse dataset such that it performs well on a variety of tasks.
2. Or train a model from scratch which results in lot of time and money and might not be that feasible sometimes.
3. Compare the results of multiple models and select the one performing the best on the desired task. The remaining models are then discarded.
But discarding the other models and selecting the best one has its own disadvantages.
A cost-effective and compelling approach is to merge existing pre-trained LLMs into a more potent model. Model merging is a relatively new method that combines two or more LLMs into a single model taking advantage of each model’s strengths, thereby boosting both its performance and efficiency.
The model EmbeddedLLM/Mistral-7B-Merge-14-v0.1 is a combination of 14 different models.

Combining models works surprisingly well and has resulted in numerous state-of-the-art models on the Open LLM Leaderboard.
How does it work?
The key principle to make models merge lies in their architecture. So far, we are limited to merging models with the same architecture and size. We should aim for a modular design and standardize model sizes to make merging easier. As merging techniques advance, it might become a simpler task.
Model merging works by combining different models with distinct areas of expertise to create a merged model that performs better than the individual source models. This process involves selecting a set of source models and integrating their knowledge and capabilities. The merged model may utilize different merging strategies, such as combining models through parameter space merging or data flow space merging. In the case of parameter space merging, the merged model is created by combining the parameters of the source models. This approach allows the merged model to benefit from the expertise of each individual model. Data flow space merging, on the other hand, involves integrating the data flow paths of the source models. This merging strategy focuses on capturing the information flow and integrating it in a way that enhances performance.
The performance of the merged models is evaluated based on benchmark tasks specific to their areas of expertise. The results show that the merged models demonstrate improved performance compared to the individual source models. By effectively integrating models with different capabilities, model merging enables the creation of models that excel in multiple domains.
This approach has the potential to unlock new advancements in AI by harnessing the collective intelligence of diverse models.
Mergekit
MergeKit is a comprehensive, open-source library designed to facilitate the application of model merging strategies. It provides an extensible framework to efficiently merge models on any hardware, supporting various merging algorithms and offering utility to researchers and practitioners. MergeKit has been instrumental in the development of thousands of merged models, many of which have evaluated at or near the top of the Open LLM Leaderboard. The library is here.
Merge Methods
The available techniques that mergekit supports are
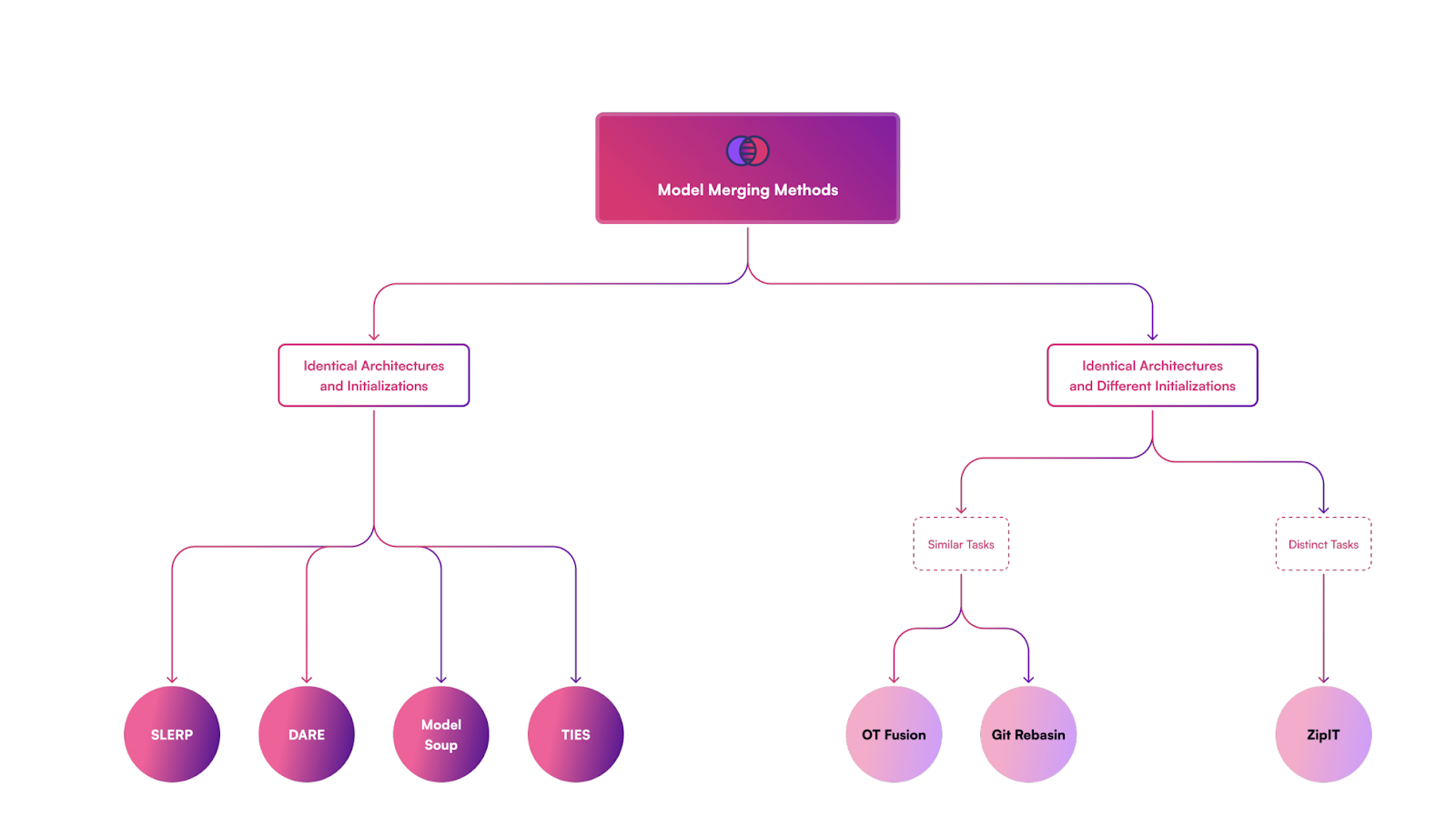
This blog covers a detailed explanation of these different model merging techniques- Linear(Model Soup), SLERP, Task Arithmetic ,Trim, Elect Sign, and Merge (TIES), Drop and Rescale (DARE) and Mixture Of Experts (MoE).
1. Model Soups :
Model soups combine multiple models by adjusting their hyperparameters based on the validation data's accuracy. These tuned models are trained using the same datasets for both training and validation and also called as linear interpolation.
Code Snippet taken from the mergekit linear method
Optionally we can add weights to the average and normalize the weights.
There are different ways to build a soup, such as Uniform soup and greedy soup.
Uniform soup is where we average all the different model variants trained on the same dataset but with different hyperparameters.
Greedy soup averages the model one by one and only keeps the ones that gradually improve test accuracy.
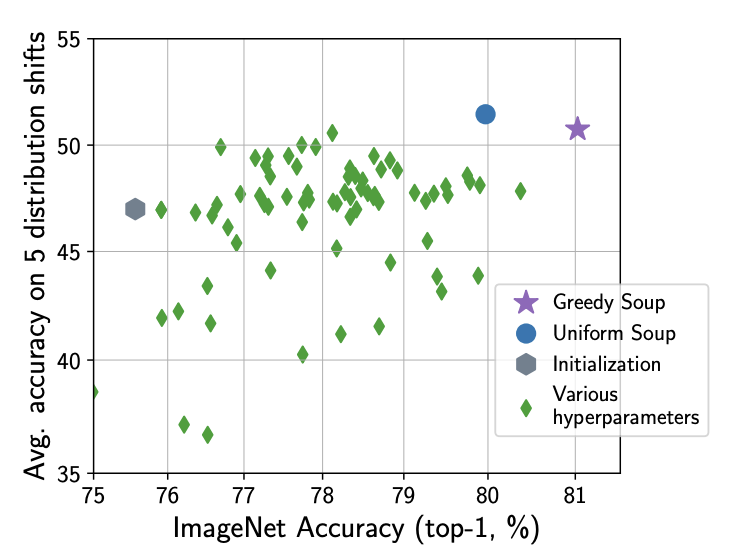
A comparison between both the soups for fine-tuning a CLIP ViT-B/32 model on ImageNet.
2. Spherical Linear Interpolation(SLERP)
The Spherical Linear Interpolation (SLERP) method merges the capabilities of LLMs by interpolating between their parameters in a high-dimensional space, treating the models parameters as points on a hypersphere.
It resolves the drawbacks of traditional weight averaging in model fusion. While a popular choice, its limitation lies in its capability to merge only two models at a time.
SLERP is utilized to smoothly interpolate between two vectors, maintaining a constant rate of change and preserving the geometric properties of the spherical space where the vectors reside.
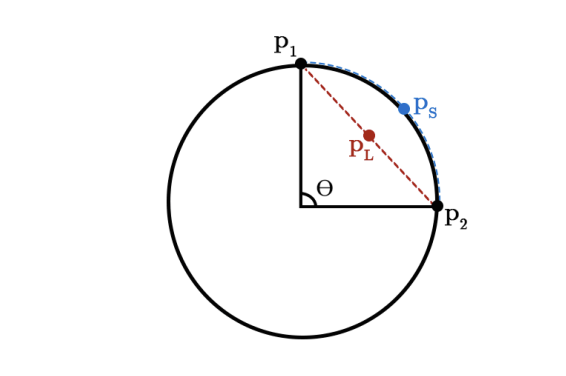
Slerp(blue curve) and linear(red line) interpolation comparison
Code Snippet of SLERP from mergekit.
2. Task Arithmetic
Task arithmetic is a simple, efficient, and effective way of editing models based on arithmetic operations over task vectors. This approach involves manipulating model behavior and performance on specific tasks by adding or subtracting model weights or task vectors. These operations are computationally inexpensive and do not incur any additional costs at inference time in terms of memory or compute resources.
Pre-trained models can be fine-tuned for various tasks such as text classification, summarization, and more. During fine-tuning, a task vector is created, representing the collection of tensor updates applied to the pre-trained model. As pre-trained models can be fine-tuned for multiple tasks across different datasets, numerous task vectors can be generated.
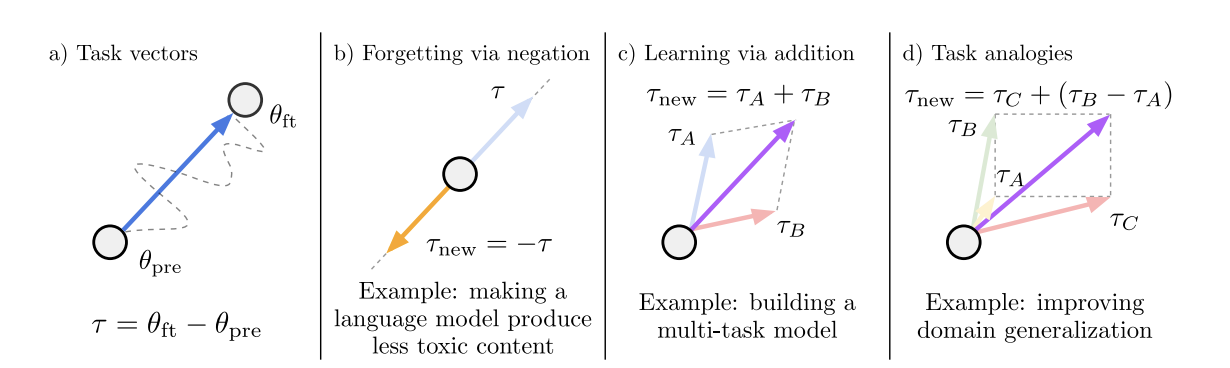
During fine-tuning, a task vector is created, representing the collection of tensor updates applied to the pre-trained model. As pre-trained models can be fine-tuned for multiple tasks across different datasets, numerous task vectors can be generated.
3. Trim, Elect Sign, and Merge (TIES)
TIES is a merges multiple task-specific models into a single multitask model without performing additional training. The method aims to address interference between parameters of different models, which can result in performance drops when merging multiple models.
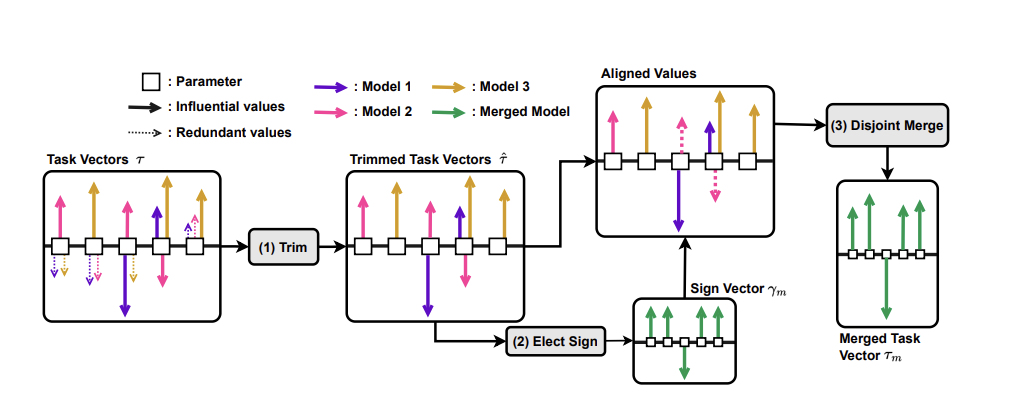
The TIES method involves three main steps:
1. Trim: In this step, each task vector is trimmed to retain only the influential parameter values by setting the redundant values in each task vector to zero. This is done to focus on the changes that happen during the fine-tuning phase of each task-specific model.
2. Elect Sign: After trimming, sign conflicts may still persist among influential parameter values. The Elect Sign step resolves these sign conflicts between different values.
3. Merge: The final step involves merging only the parameters whose sign agrees with the direction of the largest total movement across models. This step takes the mean of the values with the elected signs and the 0 for the trimmed values to produce the final parameter values for the merged model.
4. DARE
DARE is a method proposed in the document to reduce the redundancy of delta parameters in language models (LMs) without the need for retraining or GPUs. The technique consists of two main steps: dropping certain delta parameters with a specified drop rate and then rescaling the remaining parameters. Drop Step: In this step, DARE randomly sets certain delta parameters to zeros based on a drop rate $p$. This effectively eliminates a large portion of the delta parameters. Rescale Step: After dropping the parameters, the remaining ones are rescaled by a factor of 1/(1-p). This rescaling is crucial for approximating the original embeddings and ensuring that the model performance is preserved.
Implementation
The code is available on GitHub and Google Colab.
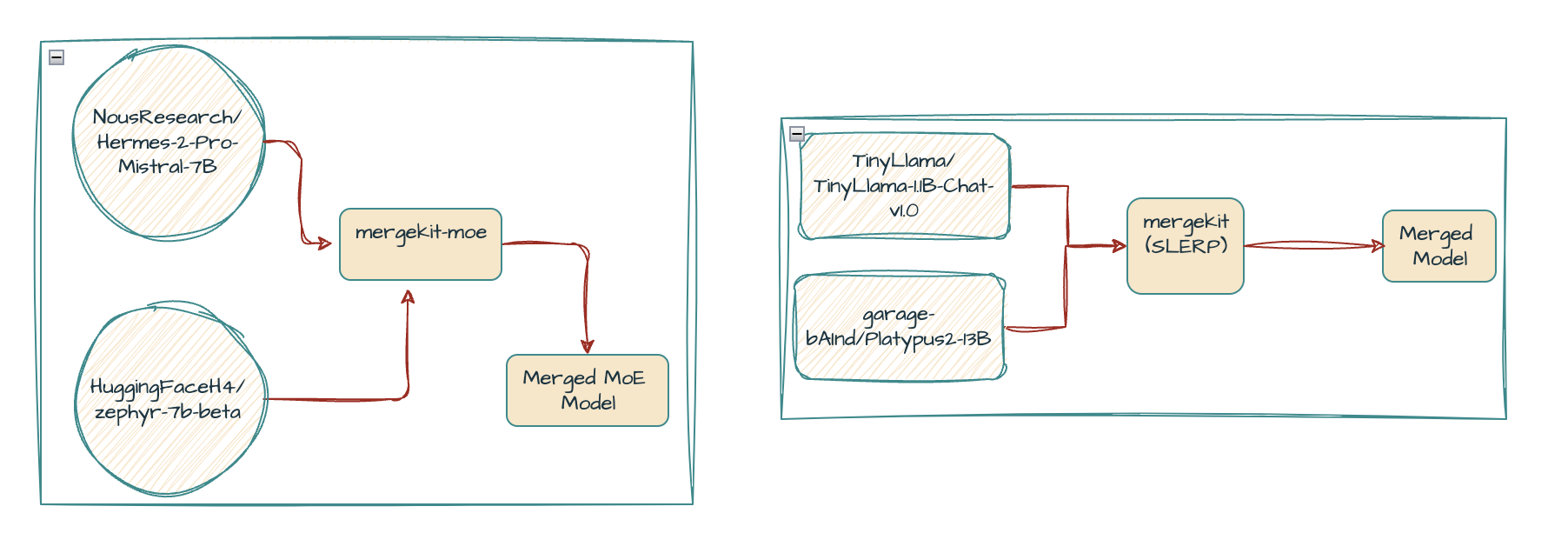
We will be merging two different models : TinyLlama-1.1B-Chat-v1.0 and Platypus2–13B using the Spherical Linear Interpolation (SLERP) method.
Using MergeKit, we can now execute the merging of multiple models.
The core of this toolkit lies in the configuration YAML file. This is where you define which models you want to merge and the base model.
Instead of merging the whole model we are only picking some layers — [0,10] in this case. The LLMs are neural networks with the concept of layers where there is the leftmost layer is the input layer and rightmost one is the output layer with numerous hidden layers in between. Layers from both the models are merged together and you can change it according to your own needs. For the sake of it, I choose only a handful of them.
Once the config file is setup and is loaded to the directory, the next step is to install mergekit directly from the source. We do this by running the command,
Once installed, we are ready to do some merge and roll.
Next we declare some variables and run the cell.
The last and final step, where we actually do the merging is this
This might take time depending on your system’s hardware, the model’s size and layers that are to be merged. The model is now merged and saved in the ‘mergekit’ directory.

You can if you want, create a README file to showcase the models you used and upload the final one on the Hugging Face Hub. To gauge your model’s performance, I would suggest the Open LLM Leaderboard, which includes benchmarks like ARC, HellaSwag, MMLU, Winogrande, GSM8K, and TruthfulQA. But don’t just rely on this and feel free to explore benchmark tools too.
Model Merging with Mixture of Experts (MoE)
Let's first understand what a MoE is,
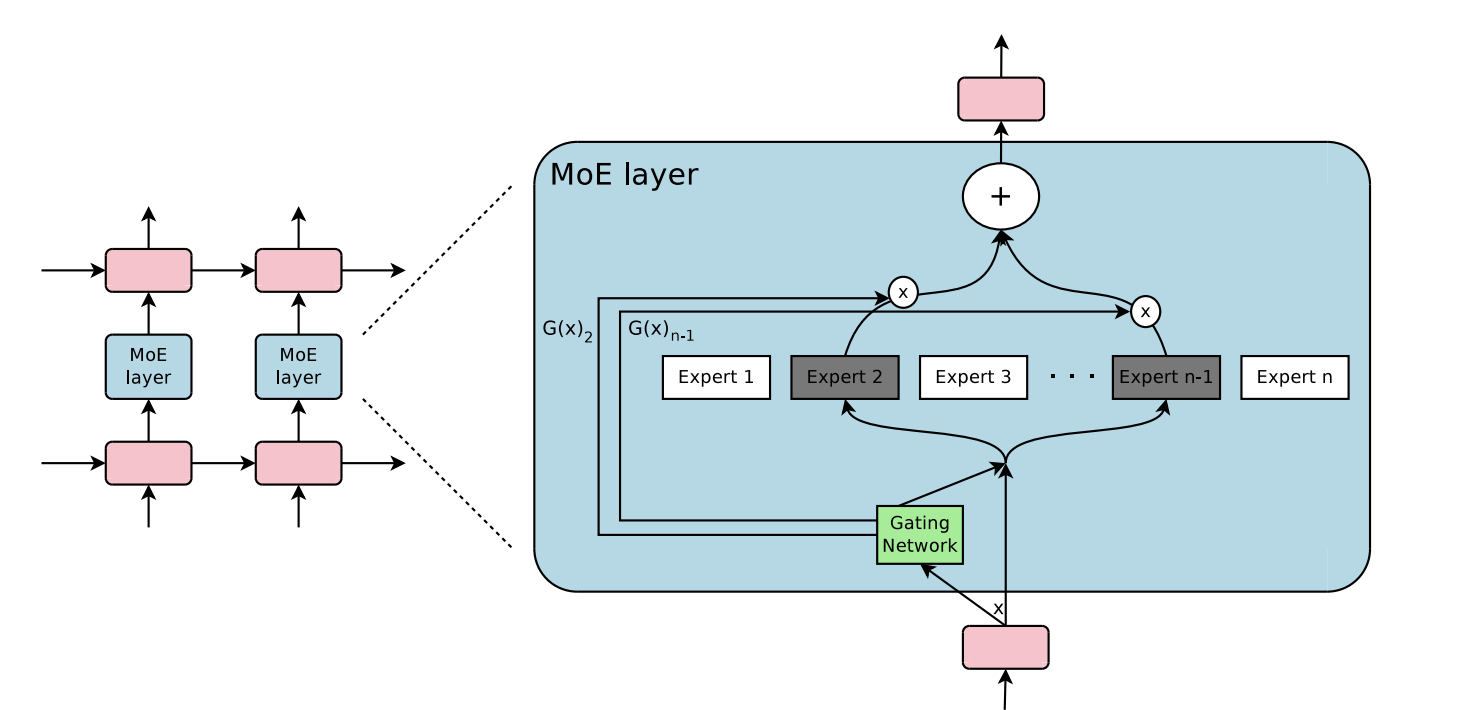
The Mixture of Experts (MoE) model is a widely studied concept in the machine learning community. It is based on the idea of combining multiple expert models to improve the performance of a neural network. The MoE model consists of a set of experts, which can be various base models. These experts share the same network architecture and are trained using the same algorithm. The MoE layer, which is an extension of the MoE model to deep neural networks, has been successful in deep learning. It contains multiple experts that are trained to specialize in different tasks. The routing or gating function in the MoE layer determines which expert is responsible for processing each input. This routing scheme allows for fast inference time by only computing the output of a few experts for each input.
The key components and concepts related to the Mixture-of-Experts:
Experts: The MoE layer contains multiple experts, which are essentially individual neural networks. These experts share the same network architecture and are trained by the same algorithm. Each expert specializes in making predictions for specific types of inputs.
Router: The router is responsible for determining which expert should be activated for a given input. It uses a gating function to route individual inputs to the most suitable experts among all the candidates. The router can route each input to the top-K best experts, where K is a predefined number, or to a single best expert.
Sparse Gating: The MoE layer uses a sparse gating function, which means that only a few experts are activated for a given input. This sparse routing scheme reduces the computation required for routing and allows for fast inference time.
Training: The experts and the router are trained using simple local search algorithms such as gradient descent. Despite being initialized from the same weight distribution, the experts can diverge to different functions that are specialized to make predictions for different inputs.
Cluster Structure: The success of the MoE layer is attributed to the cluster structure of the underlying problem and the non-linearity of the experts. The router can learn the cluster-center features, which helps divide the input complex problem into simpler linear classification sub-problems that individual experts can conquer.
Mergekit-moe
mergekit-moe is a script for combining Mistral or Llama models of the same size into Mixtral Mixture of Experts models. The script will combine the self-attention and layer normalization parameters from a "base" model with the MLP parameters from a set of "expert" models. mergekit-moe uses its own YML configuration syntax, which looks like so:
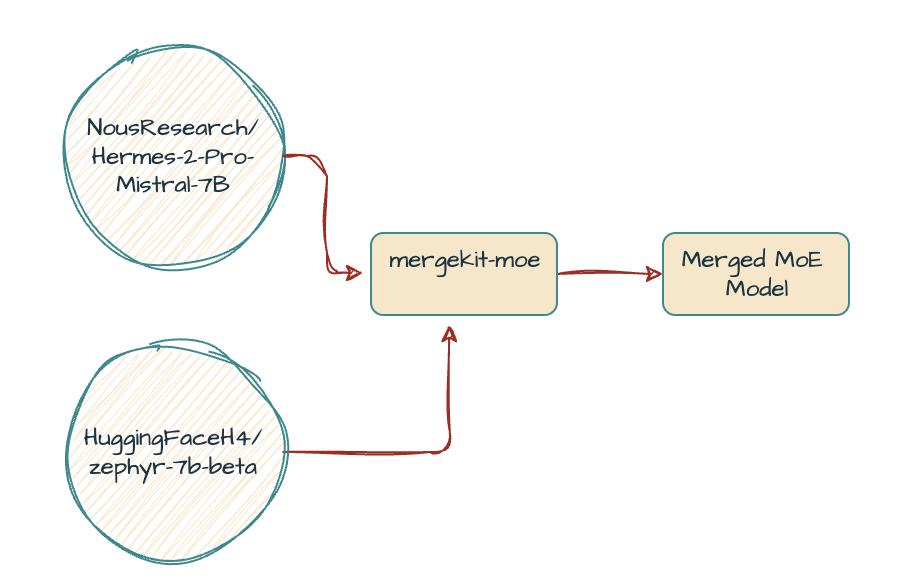
For the implementation I have chosen these 3 models with one as the base,
- NousResearch/Hermes-2-Pro-Mistral-7B (base model)
- HuggingFaceH4/zephyr-7b-beta
- NousResearch/Nous-Hermes-2-SOLAR-10.7B
For the merging process, I'll use RunPod, a cloud computing platform that offers cloud-based GPU/CPU rental services.
MoE Implementation
We begin by installing all the required dependencies,
Once that's done, we set up the config.yaml file, which is crucial because it outlines which models to merge and how to do it.
Next, we execute the merge command, which downloads the weights for all models listed in the merge configuration and applies the chosen merge method.
This might take time depending on your system’s hardware, the model’s size and layers that are to be merged.The model is now merged and saved in the ‘merge’ directory.
Next to push this merged model on Hugging face, we run the below code,
Conclusion
Our model has been merged and enjoy experimenting it Ionio-ai/ZeproSolar-2x7B.
You can if you want, create a README file to showcase the models you used and upload the final one on the Hugging Face Hub. To gauge your model’s performance, I would suggest the Open LLM Leaderboard, which includes benchmarks like ARC, HellaSwag, MMLU, Winogrande, GSM8K, and TruthfulQA. But don’t just rely on this and feel free to explore benchmark tools too.